Introduction
The lexical analyzer generator automatically construct a lexical analyzer from a regular expression description of a set of tokens. The tool construct a nondeterministic finite automata (NFA) for the given regular expressions, combine these NFAs together with a new starting state, convert the resulting NFA to a DFA, minimize it and emit the transition table for the reduced DFA together with a lexical analyzer program that simulates the resulting DFA machine.
The generated lexical analyzer reads its input one character at a time, until it finds the longest prefix of the input, which matches one of the given regular expressions. It creates a symbol table and insert each identifier in the table. If more than one regular expression matches some longest prefix of the input, the lexical analyzer break the tie in favor of the regular expression listed first in the regular specifications. If a match exists, the lexical analyzer should produce the token class and the attribute to be called to print an error message and to continue looking for tokens.
The lexical analyzer generator tested using the given lexical rules of tokens of a small subset of Java.
The generated lexical analyzer will be integrated with a generated parser which will be implemented in phase 2, lexical analyzer will be called by the parser to find the next token.
Specifications
Lexical Rules
- The tokens of the given language are: identifiers, numbers, keywords, operators and punctuation symbols.
- The token id matches a letter followed by zero or more letters or digits.
- The token num matches an unsigned integer or a floating-point number. The number consists of one or more decimal digits, an optional decimal point followed by one or more digits and an optional exponent consisting of an E followed by one or more digits.
- Keywords are reserved. The given keywords are: int, float, boolean, if, else, while.
- Operators are: +, -, *, /, =, <=, <, >, >=, !=, ==
- Punctuation symbols are parentheses, curly brackets, commas and semicolons.
- Blanks between tokens are optional.
Lexical Rules Input File Format
- Lexical rules input file is a text file.
- Regular definitions are lines in the form LHS = RHS
- Regular expressions are lines in the form LHS: RHS
- Keywords are enclosed by { } in separate lines.
- Punctuations are enclosed by [ ] in separate lines.
- \L represents Lambda symbol.
- The following symbols are used in regular definitions and regular expressions with the meaning discussed in class: - | + * ( )
- Any reserved symbol needed to be used within the language, is preceded by an escape backslash character.
Example
Input file example for the lexical rules
letter = a-z | A-Z
digit = 0-9
id: letter (letter|digit)*
digits = digit+
{boolean int float}
num: digit+ | digit+ . digits ( \L | E digits)
relop: \=\= | !\= | > | >\= | < | <\=
assign: \=
{ if else while }
[ ; , \( \) { } ]
addop: \+ | \-
mulop: \* | /
Test Program
int sum , count , pass ,
mnt; while (pass != 10)
{
pass = pass + 1 ;
}
Our Lexical Analyzer Tokens File
int
id
,
id
,
id
,
id
;
while
(
id
relop
num
)
{
id
assign
id
+
num
;
}
Transition Table
Total States: 44
Start State(s): {0}
Acceptance State(s): 40
{1} mulop
{2} addop
{3} ,
{5} (
{6} )
{7} ;
{8} relop
{9} assign
{10} id
{11} id
{12} id
{13} id
{14} id
{15} id
{16} {
{17} }
{18} num
{19} relop
{20} id
{21} id
{22} id
{23} if
{24} id
{25} id
{27} id
{28} id
{29} id
{30} int
{31} id
{32} num
{33} id
{34} else
{35} id
{36} id
{38} id
{39} float
{40} while
{41} num
{42} id
{43} boolean
| State | ! | ( | ) | * | + | , | - | . | / | ; | < | = | > | E | a | b | e | f | h | i | l | n | o | s | t | w | { | } | 0-9 | A-Z | a-z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 5 | 6 | 1 | 2 | 3 | 2 | - | 1 | 7 | 8 | 9 | 8 | 10 | 10 | 11 | 12 | 13 | 10 | 14 | 10 | 10 | 10 | 10 | 10 | 15 | 16 | 17 | 18 | 10 | 10 |
| 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 2 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 3 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 4 | - | - | - | - | - | - | - | - | - | - | - | 19 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 5 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 6 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 7 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 8 | - | - | - | - | - | - | - | - | - | - | - | 19 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 9 | - | - | - | - | - | - | - | - | - | - | - | 19 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 10 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 11 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 20 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 12 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 21 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 13 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 22 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 14 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 23 | 10 | 10 | 10 | 24 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 15 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 25 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 16 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 17 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 18 | - | - | - | - | - | - | - | 26 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 18 | - | - |
| 19 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 20 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 27 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 21 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 28 | 10 | 10 | - | - | 10 | 10 | 10 |
| 22 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 29 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 23 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 24 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 30 | 10 | - | - | 10 | 10 | 10 |
| 25 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 31 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 26 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 32 | - | - |
| 27 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 33 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 28 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 34 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 29 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 35 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 30 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 31 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 36 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 32 | - | - | - | - | - | - | - | - | - | - | - | - | - | 37 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 32 | - | - |
| 33 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 38 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 34 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 35 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 39 | 10 | - | - | 10 | 10 | 10 |
| 36 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 40 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 37 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 41 | - | - |
| 38 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 42 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 39 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 40 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 41 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 41 | - | - |
| 42 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 43 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
| 43 | - | - | - | - | - | - | - | - | - | - | - | - | - | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | - | - | 10 | 10 | 10 |
Generated NFA Graph
(click on the image for full size)
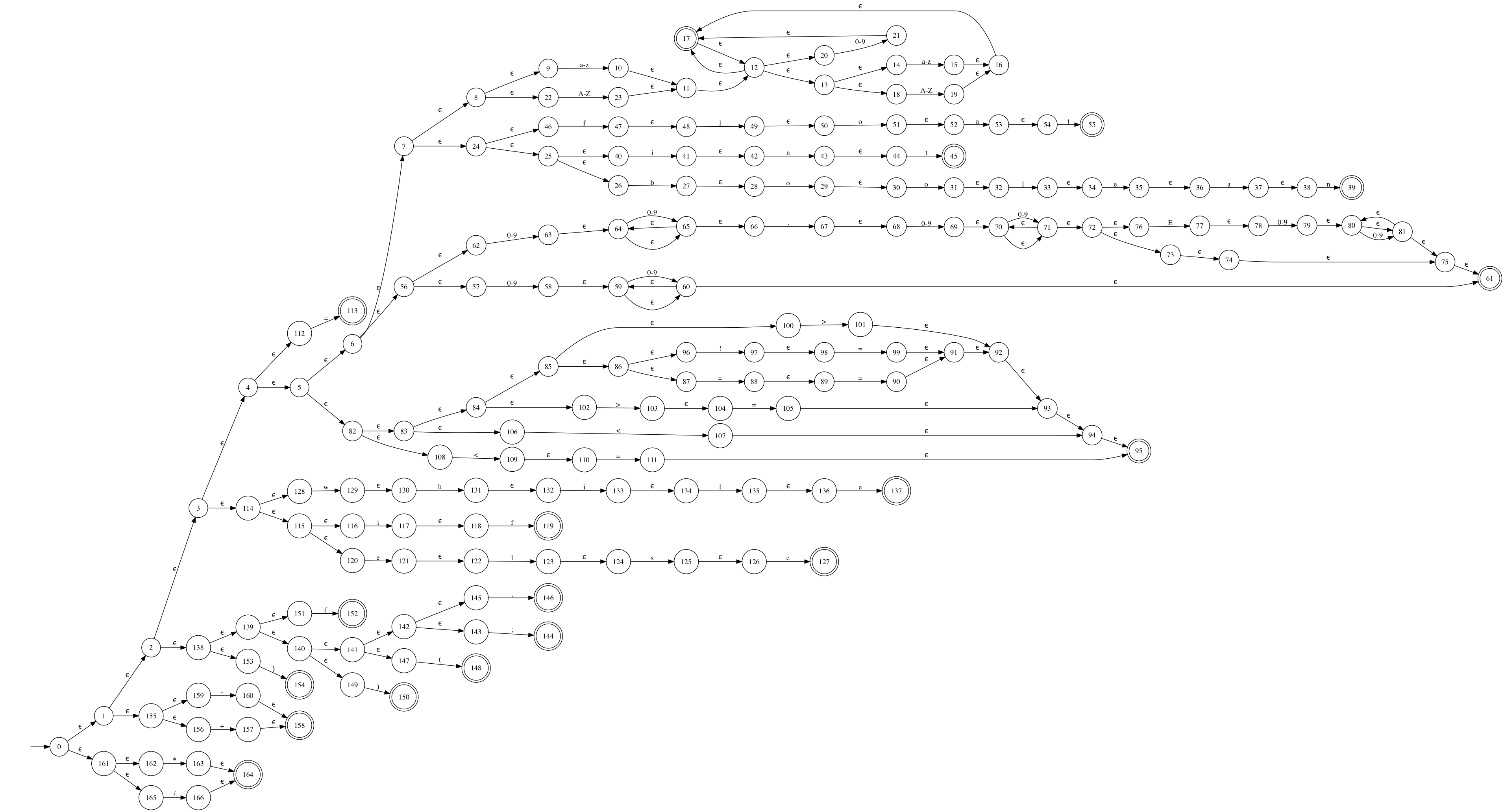
Generated minimized DFA Graph

Assumptions
- In the rules file the negative sign should be escaped (e.g addop = \+ | \-) That’s because how we handle the reserved keywords, for us the dash ‘-’ is reserved keyword to specify ranges like A-Z, and any keywords symbol should be escaped like +, *, = ..
Last Notes
- This is a C++ project, and the source code is available on github here
- The visualization tool used is Graphviz

Leave a Comment